DevOps & Site Reliability Engineering (SRE)
DevOps and Site Reliability Engineering (SRE) are fundamental practices in modern software development that bridge the gap between development and operations teams. These methodologies have revolutionized how organizations build, deploy, and maintain software applications.
In today's fast-paced digital world, businesses need to deliver software faster while maintaining high quality and reliability. DevOps and SRE provide the framework and practices to achieve this balance, enabling organizations to respond quickly to market changes and customer demands.
DevOps represents a cultural shift that emphasizes collaboration between development and operations teams. Meanwhile, SRE, pioneered by Google, focuses on ensuring reliability and scalability of production systems. Together, these approaches form the backbone of modern software engineering practices.
What is DevOps?
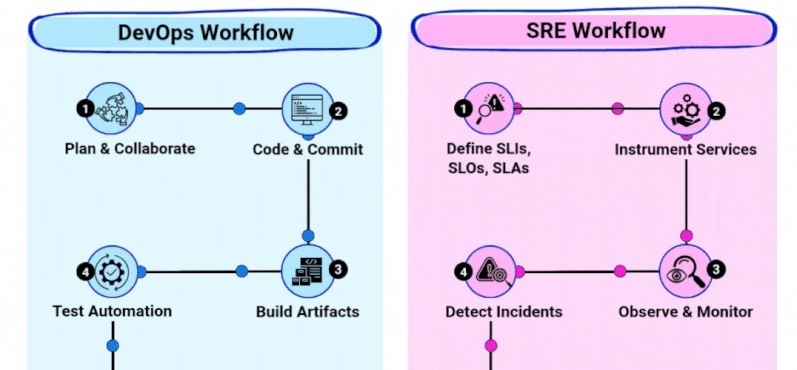
DevOps is a set of practices that combines software development (Dev) and IT operations (Ops). It aims to shorten the systems development life cycle and provide continuous delivery with high software quality.
The primary goal of DevOps is to break down silos between development and operations teams. Traditionally, developers would write code and hand it off to operations teams for deployment and maintenance. This often led to delays, miscommunication, and quality issues. DevOps bridges this gap by fostering a culture of shared responsibility.
DevOps is not just about tools; it's about a complete shift in mindset and processes. It emphasizes automation, continuous improvement, and feedback loops. Organizations adopting DevOps practices typically see significant improvements in deployment frequency, lead time for changes, and mean time to recovery.
DevOps Principles
DevOps is built on several key principles that guide its implementation:
- Continuous Integration (CI): Developers frequently merge code changes into a central repository, where automated builds and tests run. This ensures that issues are caught early and code quality is maintained.
- Continuous Delivery (CD): Code changes are automatically prepared for release to production. This ensures that software can be deployed at any time with minimal manual intervention.
- Infrastructure as Code (IaC): Infrastructure provisioning and management are done through code, enabling version control, automation, and consistency across environments.
- Monitoring and Logging: Real-time visibility into application performance and infrastructure health helps teams identify and resolve issues quickly.
- Communication and Collaboration: Breaking down silos between teams and fostering shared responsibility for the entire software delivery lifecycle.
What is Site Reliability Engineering (SRE)?
Site Reliability Engineering (SRE) is a discipline that incorporates aspects of software engineering and applies them to infrastructure and operations problems. SRE focuses on ensuring that large-scale, complex systems remain reliable, available, and performant.
SRE was pioneered at Google in the early 2000s when a team of engineers was tasked with managing Google's production systems. The team applied software engineering principles to operations work, creating a new approach to system reliability.
The core responsibility of SRE is to ensure that production services meet their reliability targets while enabling rapid feature development. SREs use their software engineering background to build systems that are both reliable and scalable, using automation to handle repetitive tasks.
Key SRE Practices
SRE encompasses several critical practices that help maintain system reliability:
- Service Level Objectives (SLOs): Defining specific, measurable reliability targets for services. SLOs help teams understand what level of performance users expect and prioritize work accordingly.
- Error Budgets: The acceptable amount of unreliability that a service can have before users become unhappy. Error budgets encourage teams to balance reliability with feature development.
- Toil Reduction: Automating repetitive, manual operational tasks. SRE teams focus on work that adds value rather than routine maintenance tasks.
- Post-Mortems: After incidents, teams analyze what went wrong, how it was fixed, and what can be done to prevent recurrence. This blameless approach encourages learning and improvement.
- Incident Management: Structured processes for responding to and resolving incidents quickly, minimizing impact on users.
- Capacity Planning: Ensuring that infrastructure can handle current and future load through forecasting and proper resource allocation.
DevOps vs SRE: Understanding the Difference
While DevOps and SRE are often used interchangeably, they have distinct focuses. DevOps is primarily about culture and process, breaking down silos between development and operations to enable faster, more reliable software delivery. SRE, on the other hand, is more specifically focused on the reliability of production systems.
DevOps can be seen as the broader umbrella that encompasses practices, tools, and cultural changes needed for modern software delivery. SRE is a specific implementation of operations-focused engineering that applies software engineering principles to infrastructure.
The key distinction is that SRE takes a more engineering-centric approach to operations, using software to solve operational problems. Both approaches complement each other well, and many organizations adopt elements of both to achieve their software delivery goals.
Benefits of DevOps & SRE
Implementing DevOps and SRE practices offers numerous benefits:
- Faster Time to Market: CI/CD pipelines enable rapid feature delivery, allowing organizations to respond quickly to customer needs and market changes.
- Improved Reliability: SRE practices ensure that systems remain available and performant, even as they scale.
- Better Collaboration: Breaking down silos leads to better communication and shared ownership of software quality.
- Reduced Risk: Automated testing, monitoring, and rollbacks minimize the impact of issues in production.
- Cost Efficiency: Automation reduces manual effort, allowing teams to focus on high-value work.
- Enhanced Security: Security is integrated throughout the development lifecycle rather than being an afterthought.
- Better User Experience: Reliable, performant applications lead to happier customers and better business outcomes.
Key DevOps & SRE Tools
The DevOps and SRE ecosystem includes a wide range of tools that support various aspects of the software delivery pipeline:
- Version Control: Git, GitHub, GitLab - for managing source code and collaboration.
- CI/CD: Jenkins, GitLab CI, GitHub Actions, CircleCI - for automating builds, tests, and deployments.
- Containerization: Docker, Kubernetes - for packaging and orchestrating applications.
- Infrastructure as Code: Terraform, CloudFormation, Ansible - for provisioning and managing infrastructure.
- Monitoring: Prometheus, Grafana, Datadog - for tracking system performance and health.
- Logging: ELK Stack, Splunk, Loki - for centralized log management and analysis.
- Alerting: PagerDuty, Opsgenie - for managing on-call rotations and incident response.
In conclusion, DevOps and SRE are essential practices for modern software development. They enable organizations to deliver high-quality software quickly while maintaining reliability and scalability. By adopting these practices, teams can improve collaboration, reduce risk, and ultimately deliver better value to their customers.